Value Level Metadata, Vertically Structured Datasets, and Normalizaton
As part of the work to implement Value Level Metadata in SHARE, as well as to author a Define-XML Implementation Guide article, this will be the first of a series of posts on the topic of Value Level Metadata. These posts target a more technical audience, however the Define-XML IG article will include less technical jargon. Future posts will cover additional Value Level Metadata topics and examples.
Value Level Metadata (VLM) is metadata that constrains a variable definition based on the value of another variable(s). VLM was originally specified in Define-XML v1.0 as a mechanism for providing the additional metadata needed for software to more accurately interpret these constrained variables. For example, VSORRES is a variable with structural metadata of DataType=”Text” and Length=”200”. However, when VSTESTCD=”DIABP” that definition is constrained by VLM to use DataType=”integer” and Length="3". In this case, the value of DIABP in VSTESTCD has triggered the application of a constraint on the VSORRES variable. This information is "value level" metadata since it varies based on the value of a particular variable, such as VSTESTCD. Building on this example VLM should also be used to specialize the definition of VSORRESU when VSTESTCD="DIABP" such that DataType="text", Length="4", and a CodeListRef is set to reference a CodedValue="mmHg". Define-XML provides the VLM for the vertically structured domains, and this metadata is not provided by the dataset itself.
In SDTM VLM is most commonly found with vertically structured Findings domains like VS. Vertically structured datasets provide a common structure that captures a variety of different observation types within a given domain. These common vertical structures are efficient to process programmatically, and allow for the easy addition of new observations. Since information from different observation types is being stored within the same structure and variables, additional metadata is needed to specify how certain variables should be specialized to match the requirements of a specific observation type. VLM is used to specialize, or constrain, the definition of those variables, such as –ORRES, based on the value of another variable, such as –TESTCD. Essentially, VLM is needed in these vertical structures so that the variables used to capture information for each unique test have a specialized specification that matches the needs of that test. For example, in the Vital Signs domain heart rate is stored as an integer, height is stored as a float, and frame size is stored as an enumerated string. VLM provides the metadata that reflects these differences.
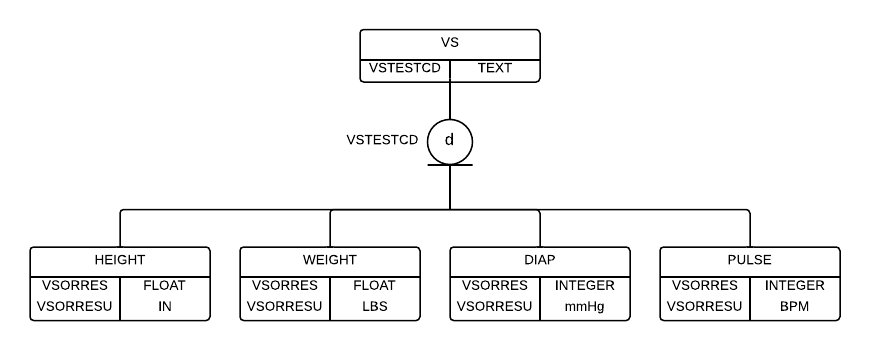
The Define-XML v2.0 specification describes vertical datasets such as those found in the SDTM Findings domains as having a "normalized data structure" typically consisting of “one record per subject per test code per visit or observation". When relational database tables are normalized each attribute column depends entirely on the primary key for a given row in the table, and all partial and transitive dependencies are eliminated. This is not the case with the CDISC vertical dataset structures. In the relational database world, these vertically structured tables might be modeled as a “specialization”. To support the specialization model, a common super-type would be created that has a specialized sub-type for each test. Each –TESTCD would function as the sub-type discriminator. In the case of the CDISC vertical table structures, VLM is needed precisely because datasets such as VS have not been modeled as normalized specializations. The VLM metadata provides the additional information needed for software to determine how each specialization should be interpreted. Thus, VLM has been created to account for the metadata missing due to the simplified design of the SDTM/SEND/ADaM datasets.
The following ERD shows Vital Signs as a specialization. The ERD has been simplified considerably to emphasize the specialization relationship at the expense of accuracy and completeness.

Comments
Post a Comment